Alright, so here’s the deal with how Tinder optimized its recommendation system by using geosharding. Basically, the team noticed their old setup—a single Elasticsearch index with a few shards—was starting to buckle under the pressure of growth. Too many users in one massive index meant slow queries and soaring infrastructure costs. Something had to change.
The Problem
Tinder’s search queries are location-based, with a 100-mile limit. For example, if someone in LA is searching, there’s no need to include folks in London. The global index was dragging things down by being unnecessarily huge. So, the team decided to break the index into smaller, location-specific chunks, which they called “geoshards.” But splitting the data evenly wasn’t enough, because population density varies—think NYC versus the ocean.
The Geosharding Solution
They used Google’s S2 library, which maps the Earth into cells based on Hilbert curves. It’s kinda like slicing the globe into small, equally-sized squares (well, almost equal, thanks to some fancy math). These cells could then be grouped into geoshards, balancing the load based on how many users were in each area.
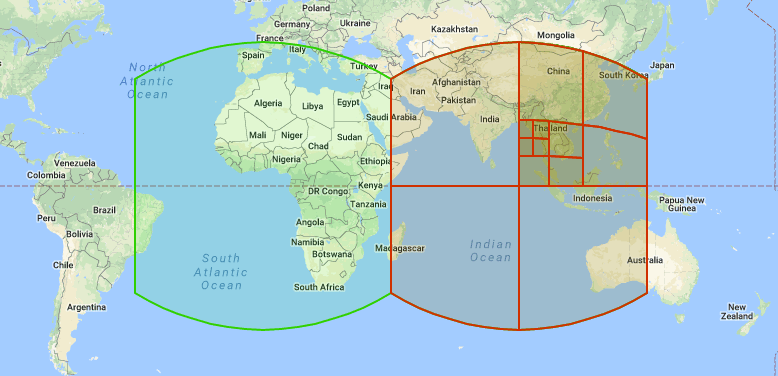
Here’s the kicker: the team had to find the perfect shard size. Too big, and queries would hit too many shards. Too small, and users moving between geoshards (like driving from Brooklyn to Queens) would create loads of messy data transfers.
Through trial and error, they landed on about 40–100 geoshards globally. That range kept things smooth, balancing speed and efficiency without overloading the system.
How It Works
To create the geoshards, they treated the Earth like a giant bucket-filling game. Imagine each S2 cell is a tiny cup of water, and you’re filling buckets (shards) as you walk along the map. When a bucket gets full, you start a new one. This way, shards stay geographically tight and balanced in terms of load.
When a user searches, Tinder only queries the geoshards that matter, rather than the whole index. For example, a 100-mile radius search might hit 3 out of 55 geoshards instead of the entire globe.
Results
This change was a game-changer. Geosharding made their system 20 times more efficient! That means Tinder could handle way more computations for the same cost, which is huge for a location-based app.
Key Lessons
- If you’re building something location-based and struggling with performance, geosharding is worth a look.
- S2 + Hilbert curves = amazing for maintaining locality. They’re like the magic sauce for mapping and optimizing performance.
- Balancing load is key. You’ve gotta measure it (like counting active users) and tweak shard sizes to avoid hotspots.
Honestly, it’s a super clever system, and the method could work for any app dealing with geo-data at scale.
Load Balancing & Scalability
Alright, so here’s how Tinder took their geosharding system to the next level. Once they nailed down the sharding logic, they built a system to handle location changes and queries like clockwork. It all flows through a service layer that maps users to the right geoshard when they move and pulls the necessary geoshards when someone searches. Cool, right?
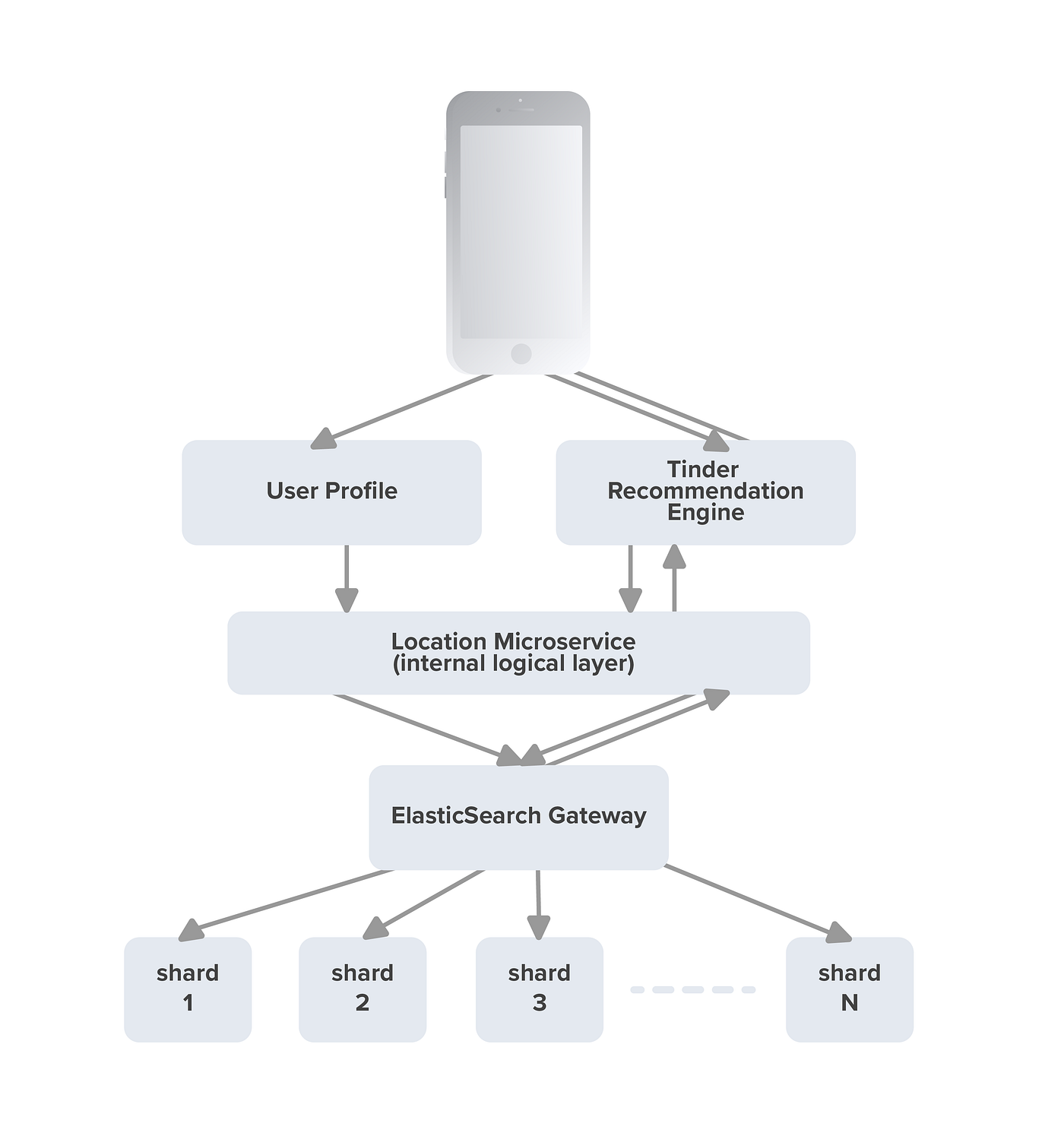
Multi-Index vs. Multi-Cluster Debate
When deciding how to actually build these shards in Elasticsearch, they had two options:
- Multi-index: All shards in one cluster, just separate indices for each shard.Pros: Easy to manage and supports multi-index queries out of the box.Cons: Scaling could be tricky when a shard gets too busy.
- Multi-cluster: Each shard as its own cluster.Pros: Easy to scale individual clusters.Cons: Elasticsearch doesn’t support multi-cluster queries natively, so they’d have to handle that manually.
They went with the multi-index setup to keep things simple and cost-effective. To handle hot shards, they leaned on load balancing strategies and replicas.
Figuring Out Shard Sizes
Next, they tackled the tricky question of how big each shard should be. Too big, and you’re wasting resources. Too small, and you’re running into overhead issues with too many shards. They used a performance testing setup with JMeter to simulate traffic and tune variables like:
- Shard size (in users and area).
- Replica count.
- Host resources (CPU, memory, etc.).
Through this, they optimized the cluster to handle Tinder’s actual traffic patterns, even accounting for quirks like dense cities versus less populated areas.
The Time Zone Problem
Because geoshards are location-based, their traffic peaks happen at different times depending on the time zone. This imbalance meant some servers would be slammed during peak hours while others chilled.
See the diagram below that shows the traffic pattern of two Geoshards during a 24-hour time span:
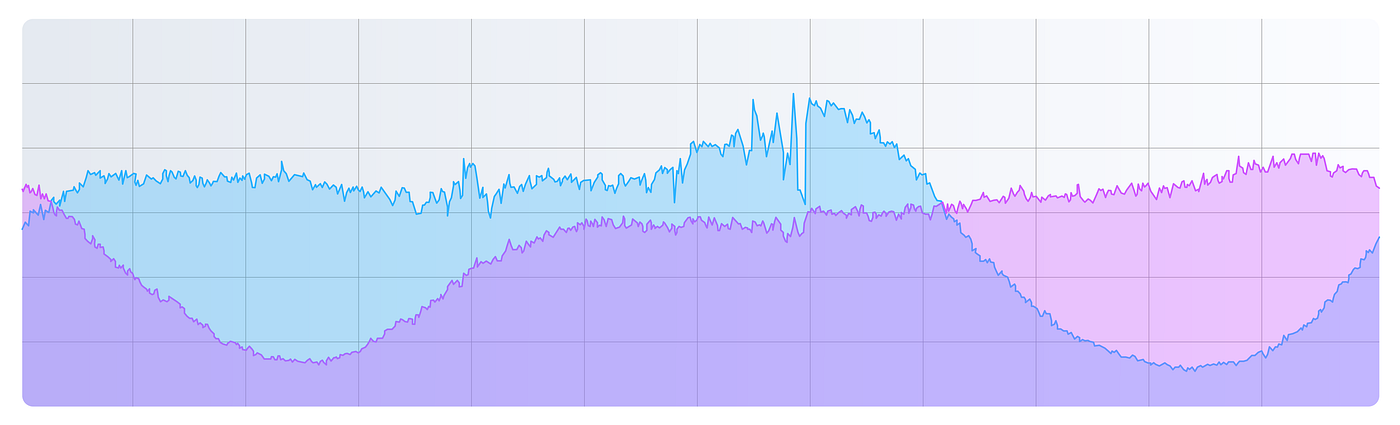
To fix it, they randomly assigned shards to servers. Instead of perfectly balancing everything (which is basically impossible), they focused on spreading the load statistically across all servers.
The Final Setup
Here’s what the finished architecture looks like:
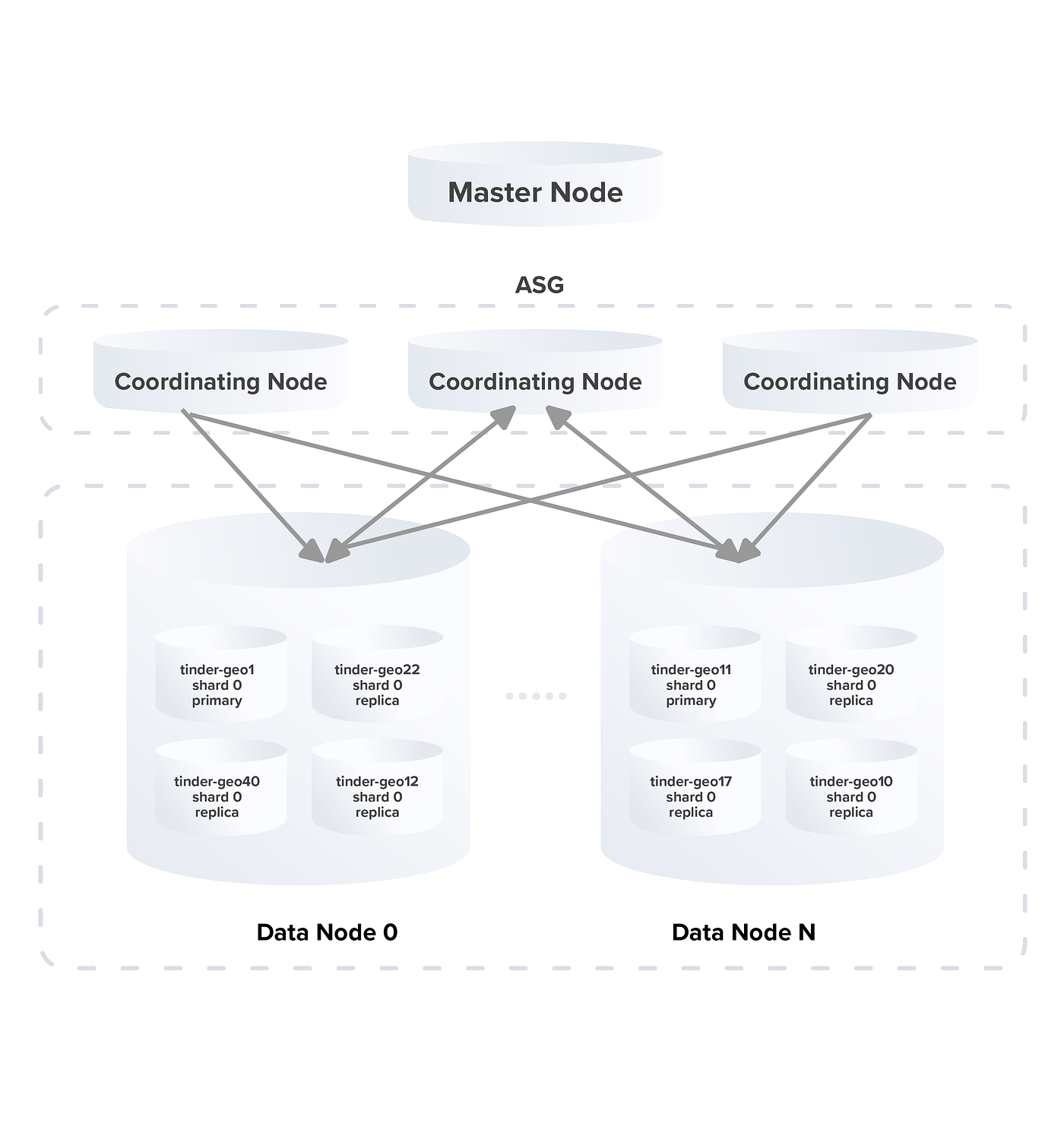
- Three master nodes manage everything.
- Two auto-scaling groups (ASGs): one for coordinating nodes (handles queries), and one for data nodes (stores the actual shards).
- Data nodes hold shards in a mix of primary and replica indices, spreading the workload evenly.
When a search comes in, the coordinating node figures out which geoshards are needed and queries the data nodes holding those shards. This setup keeps everything balanced and fast, even during traffic spikes.
Big Wins
At the end of the day, this geosharding system is a beast. Compared to their old setup, it can handle 20x more computations without breaking a sweat. The takeaways? Geosharding works wonders for location-based services, and a little randomness can make balancing complex systems way easier.
Consistency Challenges
lright, here’s the final piece about geosharding, focusing on handling data consistency and failures. So, when you’re working with distributed systems like Tinder’s setup, consistency can be a big headache. Without planning for it, you might end up with failed writes or outdated data hanging around.
Consistency Problems
Tinder’s system involves a mapping datastore (to track which geoshard a document belongs to) and the actual geosharded search indices. Things can get messy if these two fall out of sync. For example, if a user moves to a new geoshard but the system doesn’t update correctly, their profile could get stuck in the wrong location. Not great, right?
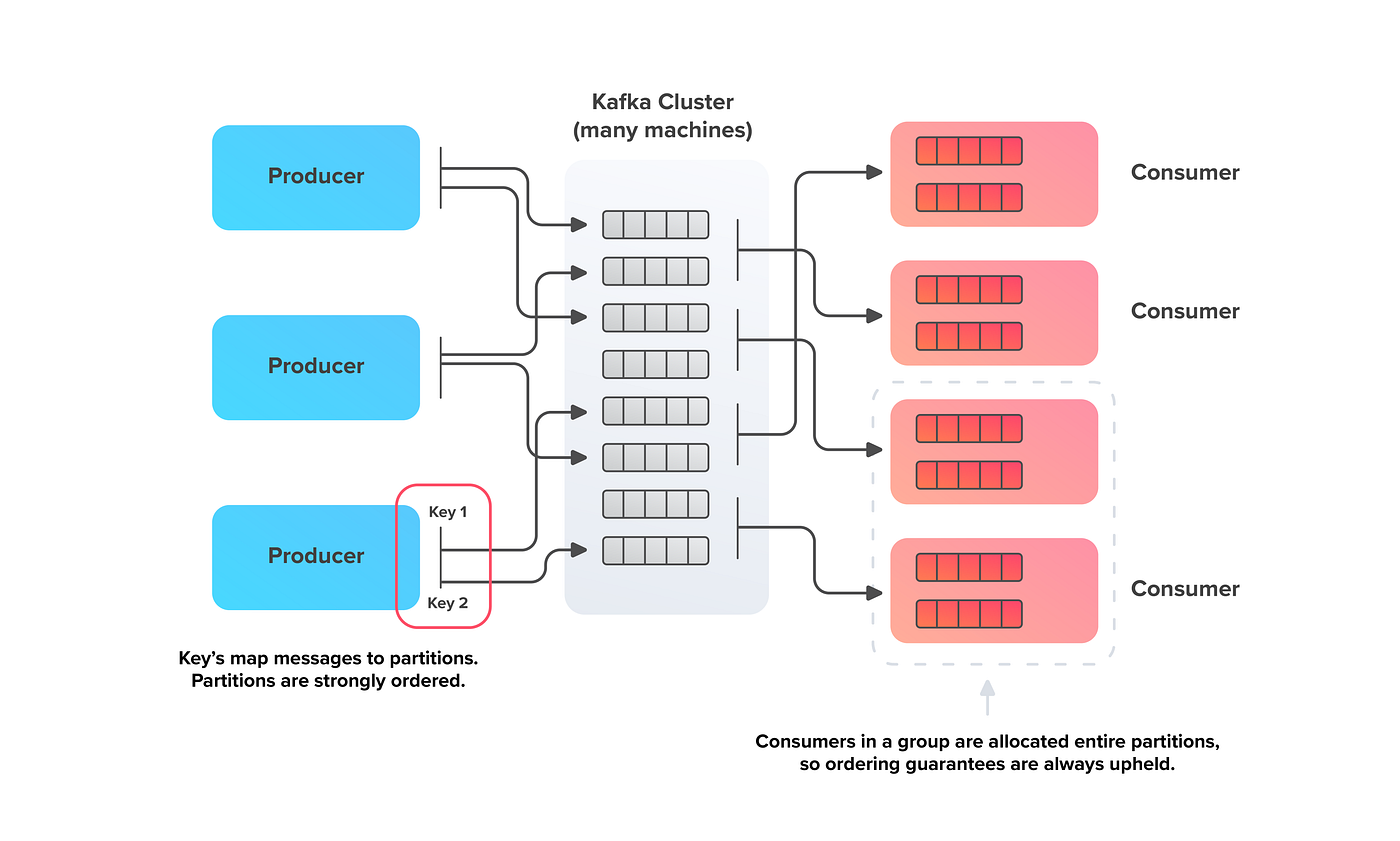
Guaranteed Write Ordering
Here’s where Kafka swoops in as the hero. Tinder needed a way to ensure that document updates happen in the correct order, especially when multiple updates are flying in within milliseconds. Kafka makes this possible with its partitions and consistent hashing. Documents with the same ID always end up in the same partition, ensuring that writes happen in the right sequence.
Other queue systems didn’t cut it—they either lacked proper ordering or couldn’t handle high throughput. Kafka? Perfect fit.
Fixing Datastore Consistency
Now, Elasticsearch (the search engine behind Tinder’s indices) is what’s called “near real-time.” It processes writes in stages, so there’s a lag before the data is actually searchable. This can cause issues when a document is moved between geoshards but isn’t fully updated in both the mapping datastore and the index.
Tinder solved this by switching from Elasticsearch’s Reindex API to its Get API. The Get API forces the index to refresh immediately when you fetch a document with pending writes. It’s a bit more work for the application, but it guarantees the data stays consistent.
They also made sure to handle cases where the mapping datastore might be out of sync—because if it’s wrong, everything else falls apart.
Expect Failures (Because They Will Happen)
Even the best systems can fail. Network hiccups, hardware issues, or upstream errors might mess things up. Tinder built in fail-safes for these scenarios:
- Retrying: When writes fail, they use exponential backoff with jitter (to avoid overloading the system) and retry. If something crashes mid-process, Kafka’s checkpointing ensures they can pick up where they left off.
- Refeeding: Sometimes data just gets out of sync. In these cases, they refeed the search index from a “source of truth” datastore. This can be done on-the-fly when inconsistencies are spotted or periodically as a background task. It’s all about finding the right balance between system cost and keeping things up-to-date.
Key Takeaways from the Geosharding Series
- If you’re running a location-based service under heavy load, geosharding is a game-changer.
- S2 and Hilbert curves are fantastic tools for preserving spatial locality in geoshards.
- Always measure load before sharding to keep things balanced.
- Performance testing isn’t optional—it’s how you avoid rollout disasters.
- Don’t overthink complex problems; sometimes randomness is your best tool.
- Keep your data consistent by guaranteeing write order and using strong reads.
- Always prepare for failures. Retrying and refeeding are essential.
In short, Tinder’s geosharded recommendation system isn’t just fast—it’s built to handle real-world chaos.
References:
- Geosharded Recommendations Part 1: Sharding Approach
- Geosharded Recommendations Part 2: Architecture
- Geosharded Recommendations Part 3: Consistency



