Decoding BERT: An In-Depth Look at the Revolutionary Language Model
Introduction to BERT: A Revolutionary Language Model
Ah, BERT, the superhero of natural language processing! Think of BERT as the language model that can decode our human word puzzles with lightning speed and mind-boggling accuracy. Imagine asking it any linguistic riddle, and POOF, there’s your answer—like magic!
Let’s dive into the realm of BERT together and unravel its secrets step by step:
Now, imagine you stumble upon this advanced language wizard called BERT. This giant among language models is here to transform our understanding of natural language by leaps and bounds. Picture BERT as a digital linguist sprinkled with a bit of magic dust.
BERT, short for Bidirectional Encoder Representations from Transformers, is not your regular J.K. Rowling creation but a creation by Google researchers. But hey, don’t worry; there are no dark arts involved in learning about this wonderful model!
Saviez-vous: BERT’s journey began in 2018 when Google’s brilliant minds introduced it in a transformative paper titled “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.”
Now let’s crack open the treasure chest to understand how this marvelous creation actually works:
The heart of BERT lies in its ability to comprehend context like a pro! It doesn’t just skim through words; it dives deep into relationships between them bidirectionally – forwards and backward – making it one heck of an expert in understanding human language quirks.
Imagine each word being VIP guests at an elite party, and BERT is the socialite who knows all their connections and histories — talk about being the life of the linguistic party!
Let me share another insider tidbit: BERT has leveled up so much that it can outshine many other models across token-level tasks (like part-of-speech tagging) and sentence-level tasks (such as sentiment analysis).
But wait, the fun doesn’t stop there! Industries left, right, and center are customizing their own versions of BERT based on specialized needs. We have bioBERT for biomedical text mining enthusiasts, patentBERT for those diving into patent classification waters, and even VideoBERT for exploring visual-linguistic wonders on platforms like YouTube.
Picture this – Training such a beast takes serious oomph! 64 custom-built tensor processing units worked round-the-clock to train colossal versions like BERTlarge in just four days. It’s like running a linguistic marathon at full throttle!
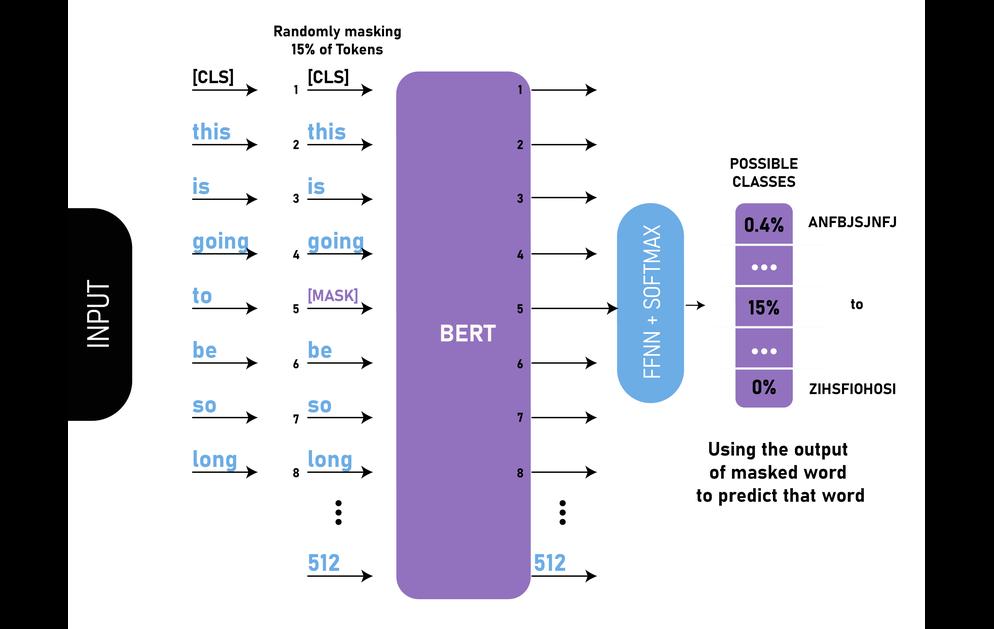
And guess what? Bidirectional pre-training is where all the magic happens – By using masked language models (we’re talking hidden word tricks here), allowing BERT to predict missing words based on their sentence buddies both ways ’round!
So my friend – are you ready to join me on this fascinating journey through the enchanted forests of linguistics empowered by an acronym named B.E.R.T? If yes then do read along…
Let’s take your knowledge a step further down NLP lane with ace courses offered by Coursera or dip your toes into practical projects fine-tuning B.E.R.T for real-world applications.
So come along as we unravel more layers of knowledge about this wonder called B.E.R.T in forthcoming sections…king insights…
How BERT Works: Architecture and Training Methods
When it comes to understanding BERT, the language model that’s taking the NLP world by storm, it’s essential to grasp how this beauty actually works in action. So let’s peel back the layers and explore the architecture and training methods that make BERT shine like a linguistic star!
- BERT, short for Bidirectional Encoder Representations from Transformers, is a revolutionary language model created by Google researchers.
- BERT excels in understanding human language quirks by comprehending context bidirectionally – forwards and backward.
- It outshines many other models in tasks like part-of-speech tagging and sentiment analysis at both token-level and sentence-level.
- Various industries are customizing their own versions of BERT to cater to specialized needs, such as bioBERT for biomedical text mining and patentBERT for patent classification.
- Training BERT requires significant computational power due to its complexity and capabilities.
Decoding BERT’s Magic: Architecture Insights
Picture this: BERT is like a symphony conductor orchestrating a masterful neural network comprised of encoder-only architecture. While traditional setups had both encoder and decoder modules, BERT flips the script, prioritizing input sequence comprehension over generating output sequences. It’s all about decoding those complex human-like linguistics with finesse!
Now, in Google’s foundational work on BERT, they showcased two main versions: BERTbase and BERTlarge. The former boasts 12 transformer layers, 12 attention layers, and 110 million parameters—a pretty robust setup! On the other hand, its heavyweight sibling, BERTlarge, ups the ante with 24 transformer layers, 16 attention layers, and a staggering 340 million parameters! It’s like comparing a smart sedan to a powerful sports car—each has its strengths depending on what linguistic road you’re cruising on!
Training Marvels: Unveiling BERT’s Learning Journey
So how does BERT go from being just another eager learner to an NLP maestro? Well buckle up because here comes the fun part! Training our linguistic hero involves two key stages: pre-training and fine-tuning.
During pre-training (imagine it as Bert studying for a massive language exam), our model immerses itself in vast troves of unlabeled text data from sources like Wikipedia and Google BooksCorpus. This phase lasts around four days where Bert hones its language skills across various domains—think of it as a linguistic boot camp preparing for myriad verbal challenges ahead!
Now onto fine-tuning—we shift gears to adapt Bert’s honed skills for specific tasks using labeled data. Picture this as Bert going from general knowledge mode to specializing in tasks like text classification or sentiment analysis—a true linguistic chameleon adapting to any discourse thrown its way!
Cracking the Code: Bidirectional Brilliance of BERT
What sets BERT apart from traditional models is its knack for bidirectional training magic! While conventional models focused on word sequences either left-to-right or combining both directions selectively during training; enter BERT stage right—embracing context from all words in every direction in sentences or queries! It’s like having eyes (or should I say “word-eyes”) everywhere, ensuring no linguistic gem goes unnoticed in its quest for deciphering human language intricacies.
So there you have it—an architectural marvel fused with intensive training methods that transform our standard perception of NLP models into an enchanting journey through textual landscapes! Excited to dive deeper into harnessing BERT’s power for practical language tasks? Stay tuned as we unleash more insights on fine-tuning this wizard for specific applications in our next segment!
Let me pose a question before I go — if you could train Bert on your favorite book series or movie scripts which one would it be? Share your thoughts below!
Applications and Use Cases of BERT in NLP
The wonderful world of BERT applications and use cases! Let’s dive into the myriad ways this language model sprinkles its linguistic magic across various NLP tasks.
Imagine BERT as your personal language superhero, swooping in to assist with tasks like sentiment analysis, chatbot interactions, text prediction, text generation, summarization, polysemy resolution, question answering—phew! The list just keeps growing longer than a Harry Potter novel!
1. Sentiment Analysis: Picture BERT as your movie critic companion determining whether that latest flick is a thumbs up or a thumbs down. It dives deep into reviews to predict the overall sentiment—talk about decoding movie emotions with precision!
2. Question Answering: Ever chatted with a smart bot online? That’s BERT using its prowess to understand your questions and provide accurate responses. It’s like having a mini-Googler at your service!
3. Text Prediction: Gmail users might have experienced BERT’s handiwork when it predicts the next word you’re planning to type. It’s like having a mind-reading assistant aiding you in composing those emails effortlessly.
4. Text Generation: From whipping up articles on diverse topics based on brief prompts to crafting captivating stories with just a few nudges, BERT showcases its creativity by generating engaging content efficiently.
5. Summarization: Legal jargons giving you nightmares? Not for BERT! It swiftly summarizes lengthy legal contracts or dense healthcare documents like a pro, making complex content digestible for all.
6. Polysemy Resolution: Words with multiple meanings like ‘bank’? No problem for BERT! It unravels the intended meaning based on contextual cues surrounding ambiguous terms—a true word detective at play!
And guess what? You probably interact with NLP and maybe even BERT daily without realizing it—NLP ninja working behind the scenes of our digital lives!
Now coming onto real-world applications – Bert isn’t just some obscure tech tool gathering dust; it’s actively shaping our digital experiences daily! For instance:
- Bert’s language prowess shines bright in AI applications for pre-training where it excels in understanding context better for enhanced search query results.
- Bert outshines other models across token-level and sentence-level NLP tasks—think of it as the linguistic MVP dominating the playing field!
With Bert leading the pack in enhancing language processing efficiency, it’s no wonder millions worldwide benefit from its powers each day—even if they don’t realize it!So buckle up as we ride through more exciting insights on how BERT transforms everyday linguistic wonders into seamless digital experiences.